


As far back as we can remember, AI strategies have revolved around the GPU. Organizations rushed to secure NVIDIA H100s, L40S GPUs, and other high-performance accelerators as demand for generative AI surged. Yet as AI systems move from proof-of-concept to production, many AI directors are encountering another problem: their powerful GPUs are chronically underutilized.
Across industries, GPU utilization rates are often stuck at 20–40%. The reason, memory architecture that’s feeding the GPUs.
At Liqid, we see this pattern in many of our conversations with enterprises, universities, and labs. Heavy investment in GPU clusters, only to watch those GPUs stall waiting for data due to memory bandwidth, capacity, and proximity required to feed that compute.
Why are traditional memory architectures are breaking down? How does this erode ROI for enterprise AI initiatives, and why Composable CXL Memory is emerging as the essential tool to achieve full GPU utilization in modern AI workloads.
Memory Wall, GPU Bottleneck: Regardless, We’re Talking About Insufficient System Memory
GPUs are designed to operate at extraordinary throughput. A single H100 can deliver up to 4 PFLOPS of AI compute, but only if data arrives fast enough. That requires strong balance between:
- Local DRAM capacity
- Memory bandwidth
- GPU-to-CPU data flow
- Latency of memory access
Unfortunately, traditional servers cannot deliver this balance. Memory inside a server is limited to the DIMM slots available, typically 1–2 TB with few systems reaching beyond that, and all memory must be physically attached to the CPU. AI workloads have outgrown those limits.
When DRAM is insufficient, GPUs experience:
- Batch size collapse
- High memory stalls
- Limited parallelism
- Lower tensor core occupancy
- Lower tokens/sec
- Higher power consumption per token
From an enterprise perspective, this means:
- Predictive models run slower
- LLM inference becomes cost-prohibitive
- RAG pipelines delay real-time workloads
- Agentic AI cycles take longer to complete
- GPU farms deliver less output per watt and per dollar
Every symptom points back to one cause: the GPU cannot operate at speed because memory cannot feed it fast enough.
Why GPUs Starve in Enterprise AI Systems
AI Models Require Far More CPU-Side Memory Than Before
Modern LLMs depend heavily on CPU-side DRAM for:
- KV-cache storage
- Attention mechanisms
- Batching coordination
- Model weights and intermediate tensors
- Embedding stores
- Graph-structured metadata
- Tool flows in agentic AI architectures
Even inference models with relatively “modest” parameter counts require hundreds of gigabytes, sometimes terabytes, of DRAM to maintain low latency.
Larger Batches Require Larger Memory Pools
Batch size is one of the biggest determinants of throughput in GPU inference. Larger batches unlock higher tensor core occupancy, better pipelining, higher requests/sec, and better amortization of overhead.
But batch size is constrained almost entirely by how much DRAM the server has.
Low memory = low batch size = low GPU utilization.
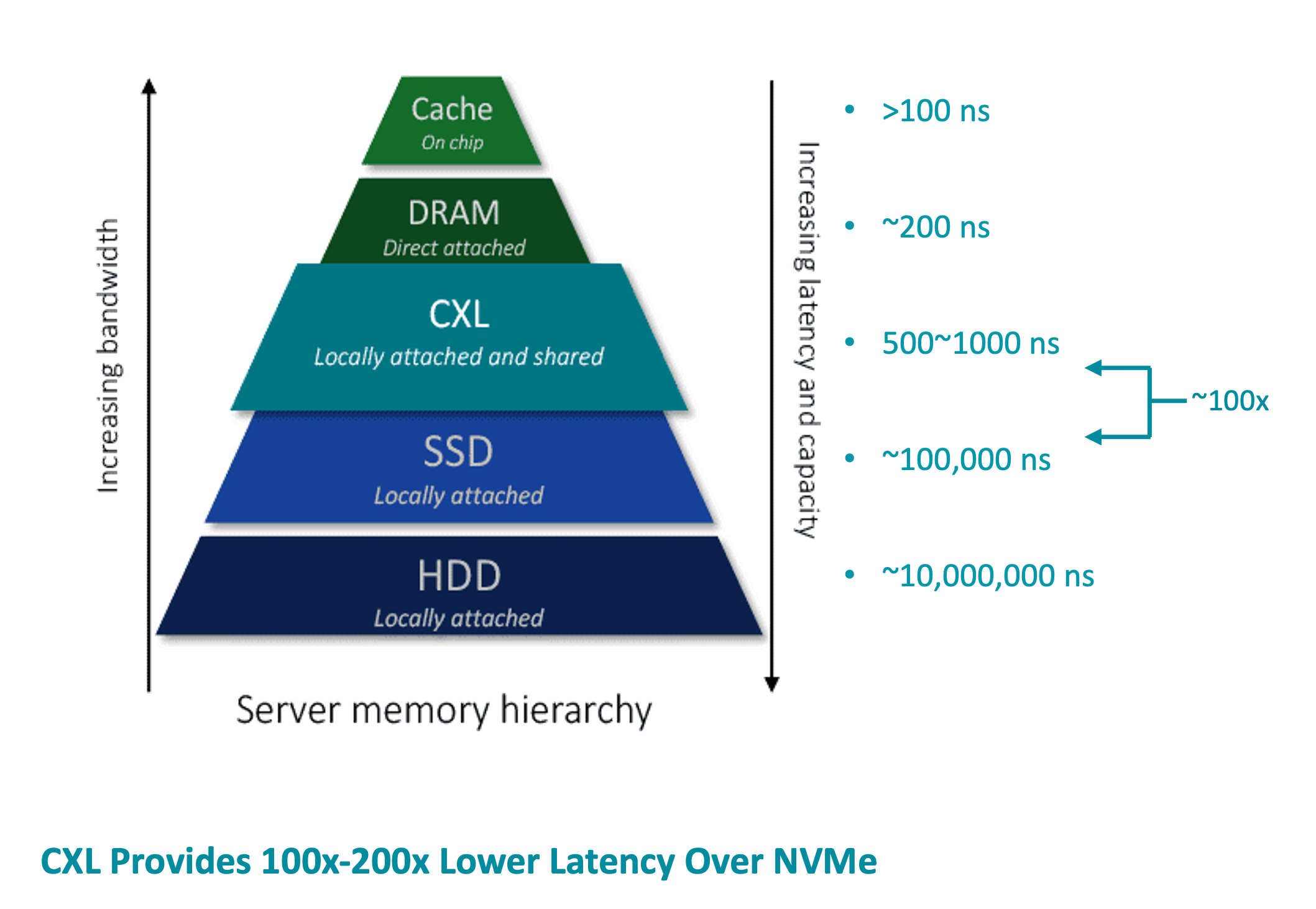
Memory Spillage to NVMe Creates 100× Latency Penalties
When systems max out DRAM, they fall back to NVMe storage with dramatically slower access:
- DRAM: ~200 ns
- NVMe: ~100,000 ns
- HDD: ~10,000,000 ns
This introduces multi-order-of-magnitude latency spikes that GPUs simply cannot hide.
Multi-GPU Nodes Are Especially Memory-Constrained
AI teams frequently deploy 2-, 4- or 8-GPU servers. Yet the attached memory does not increase proportionally. Multiple GPUs are forced to contend for the same limited DRAM.
The result is the more GPUs you add, the more underutilized they become.
The Business Impact: Underutilized GPUs Limit AI ROI
When GPUs are underfed, performance drops along with ROI. Underutilization leads to:
Higher Cost Per Token: If GPUs operate at 40% efficiency, cost-per-token effectively doubles.
Longer Time-to-Insight: Research teams, data scientists, and business units wait longer for model output.
Power Inefficiency: Idle or stalled GPUs consume nearly as much power as busy ones.
Inability to Scale Workloads: New AI use cases hit a ceiling because memory limitations gate GPU scale-out.
Diminished Return on GPU Investments: Enterprises spend millions on GPUs but get only a fraction of expected value.
Traditional server memory architectures cannot resolve this imbalance, which is why enterprises are turning to CXL-based composable memory.
Composable CXL Memory: Solving GPU Underutilization
Composable CXL Memory fundamentally transforms how memory is delivered to GPUs and AI workloads. By decoupling memory from the server and making it disaggregated, scalable, and shareable, enterprises finally get the memory pools required to drive full GPU utilization.
Here’s how it works.
Massive Memory Expansion Enables Larger Batches and Higher Throughput
With Liqid’s Composable CXL Memory solutions, organizations can scale memory to 10–100 TB per server, enabling:
- Larger batch sizes
- More concurrent inference threads
- Dramatically higher GPU occupancy
- Increased tokens/sec
This alone can increase GPU throughput by 2–5× depending on the workload.
Memory Pooling Ensures Balanced GPU-to-DRAM Ratios
AI teams often have servers with wildly different memory footprints. Composable CXL Memory solves this by pooling memory and dynamically allocating it where it’s needed most.
This prevents situations where one server is starved for memory while another sits half empty.
The outcome: All GPUs across the stack remain fully fed and ready.
Sub-Microsecond CXL Latency Keeps GPUs Operating at Speed
CXL’s near-DRAM latency ensures that GPUs receive data as fast as they need it. Instead of falling back to NVMe, workloads access memory in hundreds of nanoseconds, not microseconds or milliseconds.
This dramatically reduces:
- GPU stalls
- Memory fetch bottlenecks
- Unpredictable performance spikes
- Inference latency tail risk
Zero Application Rewrite for Immediate Benefit
Enterprises don’t need to modify models, containers, or applications. Composable memory presents itself to the OS as standard memory with zero code changes, no framework updates, and no orchestration challenges.
Major Improvements in Cost-per-GPU and Tokens-per-Watt/$
By increasing GPU utilization, CXL memory directly boosts:
- ROI on GPU purchases
- Model throughput
- Operational efficiency
- Power efficiency (Ops/W)
- Cost efficiency (Ops/$)
Organizations often see 60–75% cost reduction when GPUs operate at full utilization.
Summary: Memory Determines GPU Value
In the AI era, GPUs no longer determine AI performance on their own. Memory plays a bigger role than ever.
Without enough DRAM, delivered close enough, fast enough, and in large enough volumes, GPUs will continue to starve.
Composable CXL Memory changes that by rebalancing AI infrastructure and ensuring that every GPU you purchase delivers maximum output.
This is the architectural shift enterprises need to fully unlock AI and transform compute-bound departments into high-performance AI engines.
Learn more about how Liqid Composable CXL Memory accelerates databases.


